I love your blog design a lot. I especially *LOVE* your MONTHCHUNKS archives. (It’s tiny, clean and stylish!) Is it possible to post a tutorial on how to achieve that sort of layout? I really really wish to add the same MONTHCHUNKS to my blog :D
Sure, no problem. Back when I used Blogger to publish my blog, I wrote some JavaScript to transform Blogger’s verbose archive link list into something a little more compact. But with WordPress, I was able to write a little PHP code to get the job done on the server. Thanks to Jackson for initially suggesting I turn my Monthchunks function into my first WordPress plugin.
Output
The Monthchunks plugin outputs the links to your archives as list items by year, with a link to each month by number:
When you’re viewing a monthly archive page, the number for that month will be bold and not linked. Like the default behavior of wp_get_archives(), Monthchunks only outputs list items <li>...</li> for each year. When you call the function, make sure that it’s wrapped in <ul> or <ol> tags.
Instructions
Download Monthchunks v2.3 from the WordPress.org Plugin Directory (or from me here)
Unzip the file and upload the folder monthchunks to your /wp-content/plugins directory
Activate the plugin
Edit the theme template file sidebar.php in your theme’s directory: /wp-content/themes/name-of-theme
The monthchunks() function can take two optional parameters in between the parentheses.
<?php monthchunks(year_order, month_format); ?>
year_order is a string ("descending" or "ascending") that determines whether the years are displayed in ascending (e.g. 2001, 2002, 2003…) or descending (e.g. 2003, 2002, 2001…) order. The default is descending.
month_format is a string ("numeric" or "alpha") that determines whether the month links are printed out as numbers (e.g. 1 2 3 4…) or letters (J F M A…). The default is numeric.
If you wanted to sort the years in ascending order with letters for each month, you’d do this:
Update:This post is not intended for the faint of heart. It describes in some detail what it took for me to move my Blogger blog (circa March 2005) to WordPress 1.5. Much of it is obsolete, as WordPress 2.0 has a much simpler, more user-friendly process for importing posts and comments from Blogger. If you’re interested in moving your Haloscan comments to WordPress 2.x along with your Blogger blog, please see my “new and improved” version of this post, Importing Haloscan comments into WordPress from Blogger.
when i moved from blogger to wordpress 1.5 (a few weeks ago) the process proved to be a little less than painless. partly because the following two requirements of mine were somewhat outside the scope of the provided blogger import script.
i wanted the existing blogger permalink post urls (based on the year, month, and post title) to be the same in wordpress (ignoring the .html difference which could be solved with mod_rewrite). Update: I’ve written a new post with information on maintaining your permalinks when moving from Blogger to WordPress. (17-Oct-2006)
as a result, what you’re reading below is a partial simplification of the 3 tries it took before i was able to successfully import everything. knowing the following sql:
RENAME TABLE tbl_name TO new_tbl_name;
SHOW CREATE TABLE tbl_name;
was extremely useful when i needed to rename a table with munged data and then recreate it without reinstalling wordpress.
haloscan preparations
i had to make the following two changes to import-blogger.php (based on code written by ravingmadness) to ensure that the unique id blogger assigns to every post got included in the content of the blog post as an html comment. since haloscan uses this id to associate comments with each post, the number is crucial in maintaining that link when importing the comments later.
uncomment line 61: $post_number = $postinfo[3];
change line 127 to this: $post_content = addslashes("<!--" . $post_number . "-->" . $post_content);
it occurs to me now that it probably would have been easier to include the post id as a comment in the simplified blogger template below, rather than having to modify blogger-import.php. for an example of this, see my post importing haloscan comments into wordpress.
standard blogger import
after running the blogger import script (blogger-import.php) for the first time, it instructed me to replace the blogger template with the following:
then change a few other settings in blogger, republish the whole blog to the root wordpress directory, and finally start the import process.
maintaining the post page filenames from blogger
Update: I’ve written an additional post entitled Maintain permalinks moving from Blogger to WordPress that enables you to automatically import your Blogger permalinks (aka the “post slug”) into WordPress 2.0 along with your posts and comments. (17-Oct-2006)
in order to maintain the permalink urls for each post created by blogger, i had to make sure the “post slug” (aka dirified post title) in wordpress matched the filename of the post page created by blogger. unfortunately, blogger’s dirify algorithm is different than wordpress’, leaving out articles (e.g. “a”, “the”) and truncating the title length.
first i fixed several imported posts that didn’t have titles at all (oops). blogger still dirified them (based on the first few words of the content), but wordpress did not. luckily there were only three, which i fixed by hand:
ran the following query: SELECT LEFT(post_content,80) FROM wp_posts WHERE post_title = '';
based on the content, looked up the posts in blogger to figure out how it had dirified them
updated the post slug and title in wordpress manually
next i had to get the actual permalink urls out of blogger and into a format that i could use to compare with the newly imported posts in wordpress. i created the following template, with a tab between the two tags to get a list of the titles and their dirified permalinks.
i concatenated all the new monthly archive files blogger produced:
cat *_wordpress.php > blogger_post_titles.txt
then ran some regular expressions to clean up blank lines, removing .html on the ends of the permalinks, and the hostname/path from the beginning. at this point i had a nice clean tab-separated file of post titles and slugs to import into mysql.
i created a table in the wordpress database to store the (thankfully unique) post titles and slugs.
i used the mysqlimport utility to import the tab-separated text file into the database table.
mysqlimport -p wp blogger_post_titles.txt
the following query updated the post slugs in wordpress to be equal to the filenames i’d extracted from blogger.
UPDATE wp_posts
LEFT JOIN blogger_post_titles ON wp_posts.post_title = blogger_post_titles.post_title
SET wp_posts.post_name = blogger_post_titles.post_slug
rewrite rule to match blogger urls with wordpress permalinks
now i had to write a rewrite rule that would catch requests for the old post page urls with .html extensions (e.g. /2004/02/hello-world.html) and redirect them to urls without (e.g. /2004/02/hello-world/). figuring this out took much longer than i expected, mostly because i was trying to accomplish it with an apache redirect directive. it turned out to interact badly with the rewrite rules created by wordpress. so i ended up writing a rewrite rule instead (outside the block of rules generated by wordpress).
this was hard. haloscan allows comment exporting using the caif format, so i started by hacking up phil ringnalda’s caif2mt.php code. i got this almost all the way there when i discovered that haloscan was only exporting the raw text of the comments with none of the html tags. what a waste. i sent a support email in, and still haven’t heard back.
ravingmadness’ previously-cited post got the comment data by requesting each individual comment webpage from haloscan, scraping the page with some regular expressions, and then inserting the appropriate fields into the wordpress database. this is just what i had hoped to avoid by using caif.
unfortunately the code was a little hard to read and the regular expressions depended on a typical haloscan template layout—mine had been significantly modified. i wanted to make things a little easier on myself, so i added the raw haloscan data in an html comment beneath each actual comment, but before {HSCommentEnd}. this allowed me to write and debug the import script without having to turn off the ability to leave comments.
note: i’ve never collected commentor’s email addresses, so i didn’t bother to collect them here.
update: it occured to me that the ability to change the haloscan template requires that you’ve donated some amount of money to become a premium customer. since i imagine few people have taken that step, you may be better off using ravingmadness’ haloscan import script which uses regular expressions to extract the comment data based on the standard haloscan template.
update: ravingmadness’s haloscan import script is out of date and probably won’t work for you unless you’re comfortable hacking and debugging php. i hope to write a new and improved import-haloscan script for wordpress at some point in the future. (13-jun-2005)
update: i’ve written a script that imports haloscan comments directly from the exported CAIF files into wordpress. see importing haloscan comments into wordpress for more information. as a result you can safely disregard most of the information in this post about importing comments. (23-jun-2005)
then i wrote a script that loops through each imported wordpress post, gets the wordpress post ID and the old blogger post id from within the html comment in post_content. then it fetches the appropriate haloscan url using the unique blogger post id, parses the html for the commented out comment content, and inserts the comment fields into wp_comments. though i don’t recommend this script for public consumption it might help someone out there: import-haloscan.phps.
before using it, i’d recommend commenting out line 110 mysql_query($sql); (which inserts the comment into the wordpress wp_comments table) to make sure the code is working for you.
i just finished working on a neat referrer tracking page that displays which pages people are visiting on my site–and from whence they came, even decoding the keywords of search engine queries. check it out!
how does referrer tracking work?
unless you’ve gone out of your way to disable this feature (usually for privacy reasons), every time you click a link on a webpage, the url of that page gets sent to the webserver of the link you clicked.
for example if you click on a search result in google, the website you arrive at “knows” the url of your google query you came from–which contains the keywords you typed into google. there is even a blog plugin which highlights these keywords to make it easier for visitors to find what they were searching for.
in order to track the sites (like google) that refer vistors to your site, a service like extreme tracking takes advantage of the fact that javascript has access to the referrer URL of the current webpage. it encodes this url as a query string in what becomes a separate request for a single pixel transparent gif located on extreme tracking’s servers.
they happily provide the gif image while logging the encoded referrer url and other details of the “hit” in their database. they use this information primarily to provide a nice, free interface (with those “lucrative” google ads), detailing information about the last 20 referrers as well as cumulative hit counts over various intervals.
if you’re interested or curious to know what keywords people might be typing into google in order to find your website, that referrer information is golden. however once you start getting more than 20 hits a day, extreme tracking’s free service loses its luster.
so what did you do exactly?
a while ago i wrote a custom apache logging program that stored the raw http request information in a database, but it turns out there are these evil referrer spamming programs (e.g. Reffy) which send fake requests to webservers with referrer urls for various viagra and texas hold’em sites. so all the data i collected was littered with hundreds of bogus requests. that was a dead end.
as it turns out, extreme tracking’s use of javascript means that hits are only logged when a webpage is rendered in a web browser, causing that little 1 pixel gif to be requested. so i modeled my second attempt on that principle. i put a line of javascript in all of my webpages which triggers an image request that happens to be a php script that logs the referrer information and returns a single pixel gif. easy as pie.
then i wrote a little bit of php to decode the search engine query strings (including google’s image search!) so that i could see what search terms were bringing people to which pages on my site. eventually i may add filters and most requested lists, but right now i’m just enjoying reloading the referrer page to get a real time picture of the requests coming to my site.
after doing some research into the guts of my laptop, i discovered LCDS 4 LESS had the screen for my laptop at a much reduced though still painful cost of $495. they also said it only takes about 15 minutes to install. so i’m going to do it myself, and then probably put up the busted but working LCD panel on ebay.
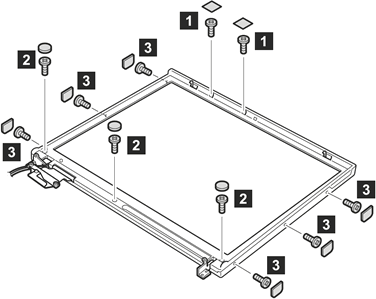
yesterday i finally had some uninterrupted time to sit down and take my laptop apart to replace the cracked lcd panel. i found a t40-series maintenance manual online which basically said take the whole laptop apart before doing anything. yeah right.
i skipped all that and unscrewed the 11 tiny screws that held the front plastic bezel in place, which i couldn’t do without first removing the 11 small black plastic stickers on top of the screws (see image below). eventually i got the bezel off (not an easy task), and then had to figure out how to unscrew the lcd screen from the support braces that held it in place. 6 screws later and the whole display unit is starting to fall apart in my hands. this is when i realize removing the whole lcd display unit from the base of the laptop might have been prudent.
i switch out the lcd screens, and suddenly find two hands are far too few when putting something back together. so jane held things in place at various angles as i tried to remember how everything fit back together.
before putting the persnickety plastic bezel back on, i powered the laptop up, and voila! 1400×1050 pixels of brilliance, not one dead or cracked. so the bezel goes back on, screws and stickers back in place, and i sit back, feeling quite smug that i saved $400 by replacing it myself in a little over an hour.
i take a break from the laptop, and when i come back to it 30 minutes later, i “wake” it from its sleeping state, it wakes, and then the whole computer just shuts off. i wonder to myself whether that battery had any charge. when i go to turn it back on, it begins starting up but immediately shuts off before getting to the IBM ThinkPad logo. “cruel gods!” at this point i’m too tired/frustrated to do anything more.
tonight, i decided to take the whole thing apart again (just to see), but this time with the speed and precision of a laptop disassembling pro. after the bezel comes off, i notice that the two wires that i thought supplied power to the lcd panel look crimped. i wiggled them, powered the laptop back on, and the screen started working, sort of.
at first it only stayed lit when i moved the trackpoint (mouse), then later (after logging in–with my fingerprint) it stayed lit permanently. i couldn’t determine a direct relationship between the wiggling of the wires and the functioning of the lcd panel. it’s almost like it took time for the power to flow all the way through the system.
anyway, it’s been working for the last fews hours without issue. i’ve restarted it, i’ve put it to sleep. the front bezel is back on, but not screwed in yet. whatever might have been wrong (any thoughts?) appears to have resolved itself in a very un-electronics like way.
with a standard html select box, you can select multiple options if the “multiple” attribute is set, but you’ve got to hold down the appropriate modifier key (ctrl on windows) in order to do so.
standard html select box
as an aside: it would be interesting to study how many people grasp the modifier-key concept and how usable the modifier key is in terms of time to complete a task and number of errors.
nevertheless “experts” tend to bemoan the usability of holding down a modifier key to select multiple options, and i would tend to agree. so after a little digging around the intarweb, i discovered three alternatives. the first is pure javascript (and less than satisfying) while the latter two creatively use checkbox widgets inside an html div to create a custom select box.
the pure javascript multiple select box grafts simple multiple selection onto an existing select box using nothing more than javascript. the downside is that it’s very blinky.
so let me throw my hat into the ring with a modification on the second example above that mixes in a little javascript to improve the visibility of the selected option and works some CSS magic to perfect the borders.