The Daily Telegraph is such a great anachronistic name for a newspaper. A name which has become so commonplace in the market that you don’t ever stop to think about what it actually refers back to. Given the pending collapse of the newspaper industry, I’ve found myself wondering: where is the Daily TCP/IP? (Or god forbid, the Daily Tweet.)
Obviously it’s all around us, the blogosphere, Google, Twitter, Bloglines, Facebook. Boing Boing probably comes the closest, as far as a functional analogue recast in the new medium, but still, for nostalgia’s sake, I’d love to see someone bring thedailytcpip.com to life.
It all started in the fall of 1998 when my dorm’s newly wired ethernet network was switched on.
Turns out a lot of my stories start like that. The computer that I’d “built” with money I received after my high school graduation transformed itself from something resembling a boat anchor into a full duplex communications device. And like many of my friends at the time, I installed ICQ. This was really my first foray into online communication, outside of my high school experience with AOL.
It was only later in college, after AOL had freed AIM from the bonds of their service, that many of my friends started signing up and spending their time chatting with each other. By then, as I recall, I’d stopped using ICQ, as part of a drive to reduce the sources of anxiety in my life. You know, like when someone I knew came online, and I’d been waiting for them to come online all day, and for some reason they wouldn’t IM me even though they could see that I was online, and so I’d wonder why they weren’t saying hi, and I’d think about IMing them, but I didn’t really have anything to say, and since I had already been online, they should be IMing me to say hi first, etc.
Much to my friends’ displeasure, I was not creating an AIM account. Apparently this was unacceptable behavior, because one day one of my friends came into my room, sat at my computer, downloaded AIM, and created a user account for me with a username that I have to this day. It’s the account I rely on for work purposes, very rarely for personal communication.
So it was very amusing to discover a few weeks ago that one of my co-workers, I’m not quite sure whom, though several were in on it, created a Twitter account for me, with the username “justinsomnia“. This is interesting I thought, given my ongoing reticence to join, “I wonder what I’ll tweet?” And sure enough they tweeted for me. What a great bargain I thought. I get to continue being a Twitter non-user, but my blog’s persona can still participate in the conversation.
I tried a few times to guess the password that they’d used, not because I wanted to shut them down, but because I thought it’d be AWESOME and surreal if fake-justinsomnia actually turned out to be real-justinsomnia. And I thought it’d really trip out whoever was responsible for creating fake-justinsomnia if someone started tweeting some eerily accurate tweets.
The game only made me a little uncomfortable when people not in on the joke started following fake-justinsomnia, some friends, and even some strangers who’d stumbled upon my blog. But honestly I didn’t really care. Well turns out I wasn’t the only one uncomfortable with impersonating me. Today I got an email saying someone new was following fake-justinsomnia. Apparently the culprit updated fake-justinsomnia’s email address to mine. And I promptly changed the password.
So now I have a Twitter account through the most circuitous path imaginable. I wonder what I’m going to tweet? First order of business: come up with a better username!
Shortly after I upgraded Stephanie’s desktop computer to Ubuntu’s Intrepid Ibex (8.10), it started acting up. Most noticeably when she scrolled Google Maps or Firefox too quickly, the display would get all garbled. I figured something in the upgrade broke support for her video card, but it happened infrequently enough that she just ignored it.
Then she started having problems where programs would just randomly crash. The symptoms were always kind of funky, like if Firefox crashed (not unusual with Flash video everywhere), we’d try to open up the System Monitor—but even that wouldn’t open. It would act like it was going to open, but then nothing would happen. Later on, I discovered that the program was segfaulting when we tried to open it:
Feb 8 21:29:55 soleil kernel: [ 4439.299147] gedit[5829]: segfault at 18 ip b70f8408 sp 00000000 error 6 in libpcre.so.3.12.1[b70e7000+28000]
Feb 8 21:30:17 soleil kernel: [ 4461.417410] gedit[7173]: segfault at bf645f9c ip b704834d sp bfa45e00 error 4 in libpcre.so.3.12.1[b7036000+28000]
Feb 8 21:30:37 soleil kernel: [ 4481.458719] gnome-system-mo[7180]: segfault at 18 ip b6c6a408 sp 00000000 error 6 in libpcre.so.3.12.1[b6c59000+28000]
Feb 8 21:30:56 soleil kernel: [ 4500.786623] gnome-system-mo[7190]: segfault at 18 ip b6c3d408 sp 00000000 error 6 in libpcre.so.3.12.1[b6c2c000+28000]
Feb 8 21:31:27 soleil kernel: [ 4531.479833] gnome-system-mo[7225]: segfault at 18 ip b6bfd408 sp 00000000 error 6 in libpcre.so.3.12.1[b6bec000+28000]
Feb 8 21:32:13 soleil kernel: [ 4577.436491] gnome-system-mo[7243]: segfault at 18 ip b6c20408 sp 00000000 error 6 in libpcre.so.3.12.1[b6c0f000+28000]
It started getting so bad that all of Gnome would crash after a while, dropping down to text-only screen of various kernel diagnostic and error info. And I honestly had no clue what was going on. So I started Googling around the other weekend, and I stumbled upon this aptly named Ubuntu support page, Debugging System Crash. The very first line said:
If your system crashes at random intervals, perform a MemoryTest first before filing any bug reports or support requests
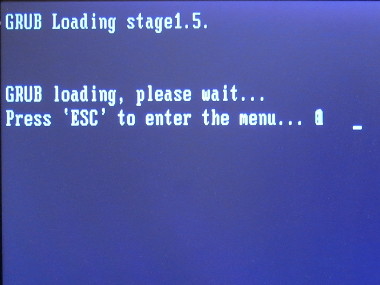
The MemoryTest page explained how to run Memtest86+. So I did that. When GRUB started loading, I pressed Esc:
And then I selected memtest86+:
At first it looked normal:
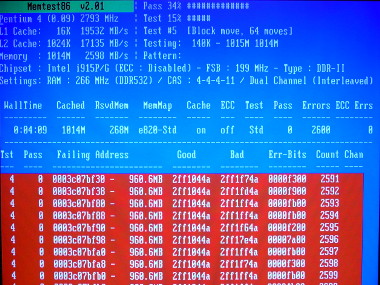
AND THEN it started barfing out all these red errors!
The errors started accumulating so fast they were just a blur:
The verdict seemed clear. In all my history of computer ownership I’ve never witnessed memory go bad—until now. So we ordered 2 gigs of shiny new memory (only $28!), which arrived tonight, I installed, and now she’s back in business.
This is not hard to do, but backing up my laptop is not something I do often enough to remember exactly how I did it the last time. Using rsync in this way is by no means specific to Ubuntu—but I imagine this guide will be particularly useful for Ubuntu users.
Setup
Plug in your external USB hard drive. Mine shows up with a mount point of /media/0435f0ab-9dfd-4d9d-ae8b-53101d419ac8, so that’s what I’m going to use below. Yours will be different. You can find out by running the command ls /media. It’s also very likely that it will show up as an icon on your desktop. Copy the UUID of the drive (that crazy string of numbers and letters) and use it in place of mine in the examples below.
If you’re only ever going to backup one computer, I’d recommend creating a directory on the external hard drive called “backup” to separate your backup from any other files you might have or might want to put on it.
cd /media/0435f0ab-9dfd-4d9d-ae8b-53101d419ac8
mkdir backup
Because at one time or another I’ve had multiple computers, I’ve tended to create directories named after the computer’s model number—x200 in the case of my Lenovo X200.
Backup
Here’s a template of the rsync command I use to backup my home directory to an external hard drive.
Replace your_username with your Ubuntu username and your_uuid with the UUID of your external hard drive. Of course also make sure that the “backup” directory already exists (if that’s where you choose to backup your home directory).
The “a” flag in -av signifies archive mode, a shortcut for a handful of other settings. You almost always want to use the “a” flag.
The “v” flag in -av signifies verbose mode, outputting a summary of the files as they are copied.
The --delete flag tells rsync to delete any files at the destination (in this case, under /media/your_uuid/backup) that are not currently at the source (in this case, your home directory).
I don’t like copying over hidden directories (those that start with “.”) which is why I add --exclude=".*/". If you really wanted an exact mirror copy of your entire home directory, then leave this out.
The slash (/) after your_username is important to prevent a directory called your_username from being created in /media/your_uuid/backup.
In the past I also included the “z” flag (as in -avz) which you’ll often see included by default in most rsync guides and tutorials. This tells rsync to compress (aka gzip) the files before sending them, and then decompress (gunzip) them after sending them. It’s a great feature for textfiles, especially when you’re sending data over a network (which tends to be slower and more costly)
However I noticed that when I was running rsync (with the “z” flag), the CPU on my laptop would shoot up to 100% and the temperature would hit 100°C. I couldn’t understand why, until I realized that most of the files I was backing up were jpegs (photos), large files which can’t be compressed, and that copying them from my local machine to the external drive was causing my CPU to compress and decompress one right after another, which was both slow, pointless, and extremely processor intensive. Leaving out the z flag speed up the operation by more than an order of magnitude, not to mention making my CPU cooler and happier.
Note: Apparently there’s a --skip-compress flag that allows you to specify the extensions of files you don’t want compress (i.e. those that are already compressed), but I couldn’t get it to work. So I submitted a bug. YMMV.
Back when I used to reserve my blog solely for personal communication, I hand coded some separate HTML documents related to my job and my grad school classes. Though both they and I have aged since then, I’ve wanted to absorb them back into my blog (much like my photo galleries) for posterity’s sake.
The one I still refer back to is my Essential Database Naming Conventions (and Style). For some reason I’ve always been into naming conventions, and still am—as the folks at work can attest. I added “updates” in a few places to point out what I do differently now. I’ve been using a “lite” version of this at work, perhaps it’s worth a 2.0 post?
State Transition Diagram for the CRUUD model was an attempt to document the work I was doing building user-interfaces on top of Microsoft Access for my job with the MEASURE Evaluation project. It’s the type of thing that’s fairly self-evident, if not quaint, but I like visual artifacts it contains.
Lastly I wrote Query Rosetta Stone to help some classmates translate between SQL and the anachronistic “relational algebra” for a databases class assignment.