cory doctorow, outreach director for the EFF
“civil liberties on the internet”
his disclaimer: this is a writer’s talk on copyright (not a lawyer’s)
copyright clause in constitution: promotes the useful arts and sciences, affords authors monopolies of limited times and scope. creators can exploit works, giving them the incentive to go on creating new works. does not give authors a perfect monopoly (different from law in other countries, e.g. france’s moral law).
congress is giving authors new copyright, taking rights away from the public. supreme court says in eldred case that 98% of works on copyright (since 1928) are not financially viable, not owned by anyone. that a work expires before copyright is in essence a “slow-motion burning of a library.”
hollywood born out of pirate film industry, 3000 miles out of reach of edison’s patent clerks in new jersey. disney creates steamboat willie in hollywood, intentionally ripping off other movies (music from steamboat bill).
a history: player pianos challenge sheet music. music industry wants an “orderly marketplace.” copyright law changes with technological trends. hollywood would not license movies to tv. walt offers disney vault to ABC, “wonderful world of color.” congress say broadcasters must license content to cable tv cos at fixed rate. sony creates betamax VCR which makes copies of copywritten work!!! congress legalizes VCR.
content protection status report (CPSR):
broadcast flag – stop internet retransmission of films, all digital television must check for broadcast flag, must be tamper resistant, which is bad for software-defined radio (GNU Radio) the “protean ur-radio”, the internet lets loose the “four horsemen of the infocolypse”: pirates, terrorist, mafia, child pornographers.
plugging the analog hole (aka “analog redistribution problem”), invisible watermark that when removed would destroy signal (not exactly feasible)
stopping P2P
cory is about to begin work for creative commons in the UK
a few days ago, i read this boingboing post about the new google “search by number” features, which i discussed in my metadata class this morning, in reference to a question about whether web search engines really use metadata (clearly they must when querying these special purpose databases).
anyway, boingboing cited aaron schwartz, (who in turn cited gary price!) and my eye caught the following snippet in his post: “in their quest to become the command line of the Internet, Google has added several new features”
“the command line of the internet”
and i was like, whoa! yes, google is like the command line of the internet. rather than clicking links or buttons, google forces people to type text, because it’s easier. if you know how to type.
but other than their stoic search box, google isn’t really like a command line at all. but what if it could be? why not design a web application that mimicked standard commandline interfaces, but was delievered via the web. type a search term. get a few results with a new command prompt. and repeat. the history of each search process would be captured within a single webpage until the user entered a command like “clear”.
here is a mock-up:
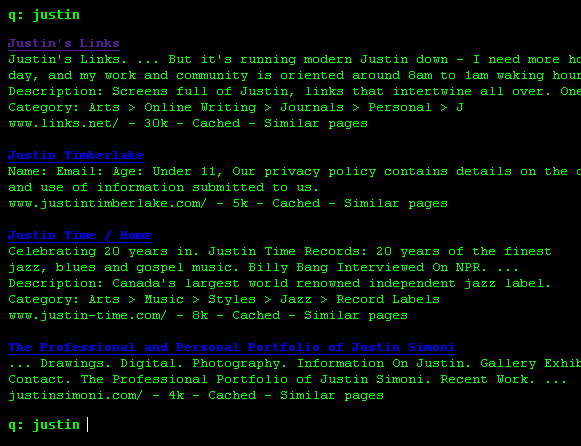
“The Google Command Line”
A functional specification for our future website, a project which, as I’m proposing, should completely obsolete the Access database work I’ve done for MEASURE over the past 3+ years, a project which I may or may not have any hand in implementing–due to the fact that my role as defined by MEASURE only encompasses “databases” (wetftm) and the responsibility of our “website” (ie, not a database) is kind of floating around in this interim ill-defined void.
So far my whole “the database is the website is the database!” spiel are falling on deaf ears.
Anyway, I’m doing what can only be described as “slogging” through the thing–I mean each paragraph is taking like half an hour–and it just occurred to me, this thing is my master’s paper.
Well a start anyway, a sort of raw infinitesimal kernel.
apparently unc’s email server, “imap.unc.edu” got fried at about 11am. so if you’re trying to send me email and wondering why i’m not responding, now you know. try some alternative methods of communication: cell, IM, and, umm, that face-to-face human verbal stuff.
one day without email. hmm. kind of reminds me of this. of course i’ve yet to really do anything productive.
note to anton and thb: i agreed to go to this xml thing tonight, not knowing it was the same time as the thb meeting. yes i’d like to assist with the website!
update: day 2 no email.
update: email is back on!!! wednesday, oct 15th, 10pm.
project: i’ve got 68 fairly structured html files (example). they contain a long, non-uniform header that needs to be junked, an <H1> title, a line with author(s), a date, some large chunks of text, and a footer that needs to be junked.
i want to write a quick program to loop through the files, parse them, and import them into a mysql table. this program will be one time use only, but having the knowledge to write this kind of program will be useful in the near future. i feel like perl is the language of champions here, but i haven’t used perl in ages. java? php maybe?
i feel like i should time myself to see how long it will take me to figure this out in perl versus just doing a whole lotta cutting and pasting (4 chunks of information x 68 documents = repetitive stress injury).
update: so far i’ve spent one hour and i’ve figured out enough perl to loop through every file in the directory, spitting out every line in each file.
final update: it took me another 3 hours to get a completely working solution. i had to figure out the perl DBI, which was actually the easiest part. mostly it just took time getting the regular expressions to do what i needed them to do. here’s the code. amazing, huh?