we heard neil gershenfeld of mit’s center for bits and atoms talk about a portable $20k fab lab he took all around the world (india on the border of pakistan, ghana) to expose adults and children to the wonders instant fabrication and custom circuit design.
jimmy wales talked about wikipedia (soon to surpass 500,000 articles in english) and the new, for-profit wikicities. says they’ll soon surpass the new york times in terms of popularity (according to alexa). sounds familiar, doesn’t it?
clay shirky and tom igoe, both from nyu’s interactive telecommunications program (itp), separately gave brilliant talks/demos of the some of the projects they and their students have been working on like pac manhattan. itp is “half engineers who care about human factors, half artisans who aren’t afraid of machines.” and/or itp is the “center for the study of the recently possible.” clay says the phone is now a universal thing that people carry with them at all times, a new addition to the purse/wallet and keys.
afternoon
joel spolsky pretty much rocked my face off. the word is his presentation may appear on the web later in audio or video form. essentially it started with brad pitt and jennifer anniston and ended with a meta-analysis of his own presentation style. somewhere in between he explained that aesthetics are everything in application/hardware design.
followed that with jason fried giving his development mantra developed during the making of basecamp. he said embrace your constraints. and some other stuff.
danny hillis of applied minds demoed some of their mindblowing work, much of it in robotics and hardware, but really in every conceivable technological field.
imagine a plasma screen tv oriented like the surface of a table, with a touch sensitive surface that you could use to manipulate a global map interface. zoom from earth to high resolution images of actual buildings, swipe various layers of GIS information across the map. he showed a video of this demo given to an esri conference of geographers, which he said brought some of them to tears—then he showed us the next version with a “programmable surface”, which deformed to the surface chacteristics and elevations of the map.
super great talk about von neumann, by george dyson, brother of esther dyson and son of freeman dyson. grew up in at princeton’s institude for advanced study in the shadows of einstein, godel, turing, and john von neumann–the man credited with inventing the modern computer architecture.
dyson got access to several boxes of archives from the ias with details of their original computer development activities, which he had annotated and assembled into a very engaging, entertaining presentation about some of the history of our collective hacker culture.
lunch
vigorous discussion with patrick on microsoft, mozilla, open source, web standards, economics, etc. over a juicy pub burger.
so far this morning stuck in an elevator with doc searls and dave winer (update) dan gillmor’s brother, steve, at etech just before the second floor. we had to use the secret red telephone to call support and get us out.
when they pried the door open, dan gillmor was outside taking pictures of us with his cellphone. i expect to see them shortly on flickr. will post here.
last night patrick and i made our way out to the yardhouse (thanks corey!), just two blocks from the hotel, where they serve draught beers in glasses a half-yard and a full yard tall–in addition to pints and steins. patrick managed to put away two (half yards), i stuck with one rogue dead guy ale, fully accepting the fact that during this trip patrick can (and will) drink me under the table.
by the time we got back to the hotel it was around 11pm local time–or 2am est. we were done.
etech day one
the morning’s tutorial on web services was ok. it didn’t seem very “emerging” as much as “summarizing.” that said, the lead developer of flickr (everyone’s FAVORITE app) and one of the developers of 43things were on the panel. they took a shot of the audience and i annotated it.
took a walk in the sun to check out the nearby water with patrick and made it back just in time for the atom talk by a bekilted ben hammersley. which i thought was quite good, definitely enlightening.
after a break of laptoping, we listened to brendan eich talk about all things mozilla for an hour and a half. lots of good stuff there.
bumped into paul jones and dan gillmor in the lobby on the way out to find dinner. enticed paul with the promise of food, gorged ourselves on curry, caught up on the latest unc tech gossip, and rolled ourselves back to the hotel, where i find myself now.
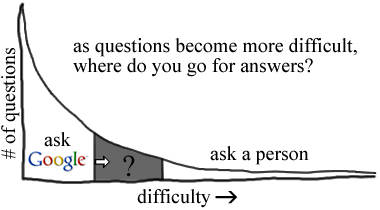
so i was writing jackson an email, we’ve been going back and forth about wordpress, and i find that when i’m asking a question, a second or two after i’ve taken the time to explain what i’m asking, i’ll check with google just to see if the question is worth asking a person, and quite frequently i’ll find several bits of interesting and semi-relevent information.
by the time i get back to the email, the original nugget requires significant retooling based on what i’ve discovered. as result, my emails often have these annoying grammatical errors and typos from quick surgery of ideas without careful resyncing of tense, person, and number. sometimes, depending on the circumstances, the cost of fixing the email is too great and the assumed benefit for the recipient is too low to make it worth sending.
all this makes me think that the world of information can be divided into questions where the answer is easy to coax out of google, and questions where it’s not. of course google is steadily chipping away at those hard questions, but bloggers also, by contributing vast amounts of freely accessible information to the web, are solving the problem from the bottom up. by adding answers.
this would be interesting to study, but difficult. what is a question? how do you track questions that are not asked of google? how do you rank the objective difficulty questions? one possibility: rather than using naturalistic data, come up with a standard battery of questions and have subjects choose where they would go to find the answer (google, a friend, a librarian) and how difficult they think the question is on a likert scale (before and after finding the answer). a likert scale would put a cap on the long tail–unless you factor in the time it takes to find the answer.

{kind=link}