Having designed and redesigned countless user-interfaces, some for the web, and many using Microsoft Access, I’ve started more religiously employing the CRUD model, which stands for “Create, Retrieve/Read, Update, and Delete”. These are the four major functions a user-interface–especially one the interacts with a database–must perform.
Most users now expect fairly robust “undo” functionality, therefore I’ve added a fifth function to the paradigm, “undo”, giving birth to a new acronym: CRUUD (pronounced /crude/). The undo action provides an important alternative to the update action.
CRUUD State Transition Diagram
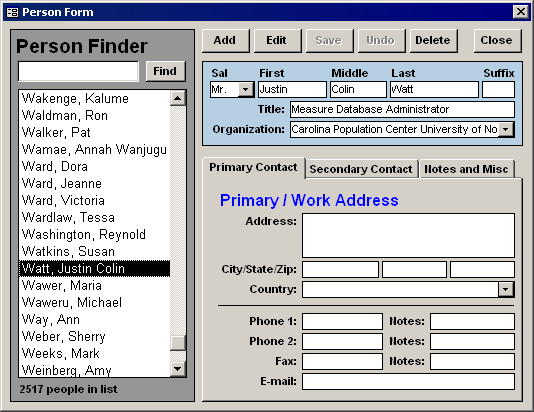
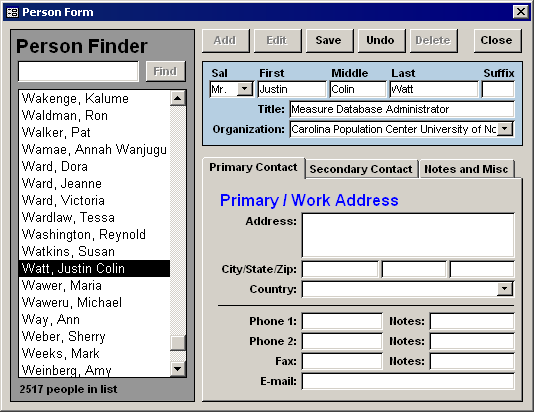
The diagram above is my present vision of how a professional user-interface should respond to user-interaction. The blue rectangles are the two main states, and in many cases are the same user-interface. The pink rounded rectangles represent the user-triggered events (usually implemented as buttons). The logic that the system performs in response to those events are captured in the diamonds and parallelograms. Below I’ve included two screenshots of a user-interface in both of the two states.
Person Form in Review ModePerson Form in Edit Mode
eliminates question of proper case as well as errors related to case-sensitivity
speeds typing rate and accuracy
differentiates table and column names from uppercase SQL keywords
separate words and prefixes with underlines, never use spaces
promotes readability (e.g. book_name vs. bookname)
avoid having to bracket names (e.g. [book name] or `book name`)
offers greater platform independence
avoid using numbers
may be a sign of poor normalization, hinting at the need for a many-to-many relationship
table names
choose short, unambiguous names, using no more than one or two words
distinguish tables easily
facilitates the naming of unique column names as well as lookup and linking tables
give tables singular names, never plural (update: i still agree with the reasons given for this convention, but most people really like plural table names, so i’ve softened my stance)
promotes consistency with naming of primary key columns and lookup tables
ensures alphabetical ordering of a table before its lookup or linking tables
avoid confusion of english pluralization rules to make database programming easier (e.g. activity becomes activities, box becomes boxes, person becomes people, data remains data, etc.)
SQL statements read better, e.g. SELECT activity.name vs. SELECT activities.name
avoid abbreviated, concatenated, or acronym-based names
promotes self-documenting design
easier for developer and non-developer to read and understand
prefix lookup tables with the name of the table they relate to
groups related tables together (e.g. activity_status, activity_type, etc.)
prevents naming conflicts between generic lookup tables for different entities
for a linking (or junction) table, concatenate the names of the two tables being linked in alphabetical order
orders linking table with a related entity table
expresses composite purpose of the table
this should be waived if the linking table has a natural, standard, or obvious name (e.g. “item” in: [order] 1 to M [item] M to 1 [product])
this must be waived if there are multiple linking tables between the same two tables, (e.g. “student” and “instructor” between the tables “person” and “class”)
rare problem
what about a linking table for a generic lookup table?
this can be avoided by renaming the generic lookup (and removing the prefix)
suggestion: as a variation on the linking table naming convention above, use a special character (such as a plus-sign “+”, a hyphen “-“, or a double-underline “__”) to separate concatenated table names (e.g. the linking table for activity and activity_type would be activity__activity_type)
column names
the primary key should be the singular form of the table name suffixed with “_id” (update: i now just name all my auto-increment primary keys “id”, however i’ve left the old rationale below)
allows primary key to be deduced/recalled from the table name alone (e.g. primary key of the product table would be product_id)
consistent with the name of the foreign key
prevents having to alias primary keys in programming
prefix the name of every column with the table name, excluding foreign keys (update: i no longer follow this convention because it’s very tedious to type, and because it’s obviated by the use of abbreviated table aliases in SQL)
prevents using “name”, “order”, “percent”, etc. as column names and clashing with SQL/RDBMS reserved words
creates near unique column names (e.g. product_name, product_code, product_description, etc., often simplifying query design and SQL coding, recommended for PHP)
makes the column names consistent with the primary key
differentiates foreign key columns from columns native to the table
maintains semantic transparency of column names when using table aliases (e.g. SELECT a.activity_name FROM activity a)
prevents naming a column the same name as the table
this can be waived for databases with many tables (30+), tables with many columns (30+), and long and obviously unique column names
this can be waived if your database programming always refers to columns in the form tablename.columnname
foreign key columns should have the same name as the primary key to which they refer (update: obviously now that i just name my primary keys “id”, i name my foreign keys the singular form of the table name + “_id”)
makes the table to which they refer completely obvious
if there are multiple foreign keys referencing same table, prefix the foreign key column name with an appropriately descriptive adjective (e.g. lead_person_id, technical_person_id, etc. which transparently reference person_id in the person table)
suffix date-type columns with “_on”, suffix datetime-type columns with “_at”, and prefix boolean-type columns with “is_” or “has_” (update: i now tend to use the “_date” suffix for date-type columns and “_time” for datetime-type columns—even if they are stored as integers)
prevents confusing with more common text/number data types
one solution to solve the problem entails creating a sort of proxy code for each training that combines something from the program type, the organization, and the training tables.
for instance, RW-MAH-2002 would stand for “Regional Workshop at Mahidol University in 2002.”
if the information sought was known in advance, the index could be navigated quicky to find the appropriate record.
on the otherhand, if only part of the sought after information was known, a little about what the composite index means could be inferred from its structure, allowing the user to learn quickly and browse intelligently–skipping irrelevant records.
the problem with this solution is that the composite proxy index does not include any piece of information from the program table. (though the available data shows no such cases, it is conceivable that there may be more than one regional workshop in Mahidol in 2002, thus RW-MAH-2002 ceases to be unique).
using some sort of incremental notation might suffice: RW1-MAH-2002, RW2-MAH-2002, except that incremental notation is essentially random, and forces the unacquainted user to browse several records before settling on the training they intended.
the optimal solution would involve creating a program abbreviation or acronym that would differentiate one workshop from another of the same type at the same place. this adds a bit of complexity as the program abbreviation would have to be unique from other programs that have the same type and organization.
here frequency must be balanced with usability. if the cases where conflict exists are so infrequent, the burden of an incremental conflict avoidance solution is much less than requiring program abbrevations in all (or worse, some) cases, especially for hard to abbreviate programs like “evaluating the impact of population, health and nutrition programs.”
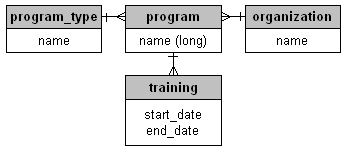
i am trying to design an interface to browse a list of trainings.
each training belongs to a program, and a program has a hosting organization (like university of costa rica), a program type (like master’s degree or workshop) and a name which is usually really long and hard to differentiate from the other program names (like “evaluating the impact of population, health and nutrition programs”)
finally each program can have one or more training instances which are differentiated from each other by their start and end dates.
for the entity-relationship diagram aware, this looks like:
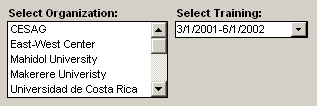
i am implementing this in Microsoft Access, which means the only ‘widgets’ i have to browse this information are listboxes and comboboxes:
(since radiobuttons, checkboxes, and togglebuttons must be placed on the form in advance for each option, like for each program type, they are not as useful for browsing)
some problems with these widgets:
– once you place the widget in the form, you can’t programmatically change its shape or size or position depending on the amount of data in the list
– names longer than the width of the list do not wrap
– listboxes are effective for browsing, but unlike web-based user-interfaces which can scroll for many pages, in Access the entire user interface form should be visible to the user without scrolling
so i’ve been to some crazy places in my short life, but never to florida. which you, dear reader, must be thinking i should remedy. well, alright, i’ll go.
actually i’ll be in ft. lauderdale, a place which i seem to have an awfully hard time pronouncing, for the annual ACM conference on computer human interaction (CHI 2003)
in addition to this being my first trip to florida, this will also be my first academic conference. i’ll be hanging with abe, marchionini, wildemuth, and a bunch of rad and possibly famous human-computer interactors.
and as is my habit/affliction, it is nearly 2am, i haven’t even started to think about packing, and abe’s coming to pick me up at 8am.