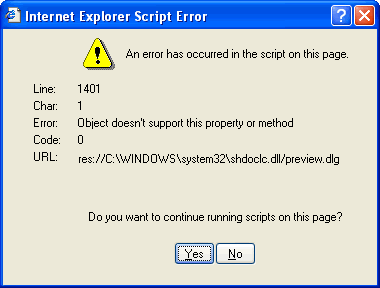
Got bit by the IE id="tags" printing bug on Java.net today. Eric Meyer (of CSS fame) describes the bug on his blog here: Reserved ID Values?
Basically if a page has an html tag with with id="tags" as an attribute, when you try to print in IE you’ll get a fun error message:
And you can’t print the webpage.
Of course one of articles on Java.net had just that, so I removed the unnecessary id="tags" and lo and behold…the problem did not go away. So it took me some time to discover that name="tags" is also persona non grata in IE, something that hadn’t previously been described in Eric’s post.
So the moral of the story is, avoid using tags as the id or name of any HTML tag.
This post first appeared on From the Belly of the Beasts, a weblog from some of the people who build O’Reilly websites.
So I’ve been thinking about standardizing how we “syndicate” posts (or blurbs) in HTML. Currently the decisions about how to organize divs and what to call classes are fairly arbitrary. But if there was a standard and predictable way of organizing what is essentially structured data, then we’d have a much easier time building stylesheets and dealing with edge cases and contingencies.
There are two problems that this proposed microformat and its associated CSS recommendations are meant to solve. The first is preventing excessively long text (usually long hyperlinked URLs) from breaking out of the post-content container. The second is preventing floated blocks (usually images) from breaking out of the bottom of the post-content container.
As I understand it, with microformats the choice of which tags to use (h1 vs. h2 vs. div) and the hierarchical location of the tags is not nearly as important as a standard lexicon of class names. In the syndication world, the RSS’s use item to refer to a chunk of content and Atom uses entry, neither of which I like. I’ve used blurb as a class name previously, usually because I was structuring blurbs and not full content. However this format should work for both blurbs and full content items, in which case I think post is the most appropriate. But I could be persuaded otherwise. My concern is that it’s not sufficiently generic. Would it make sense to call a full text article a post?
Some optional classes might include: post-date, post-byline
Blog Post Microformat Illustration
div.post
div.post-header
h1.post-title
div.post-content
div.post-content-footer
div.post-footer
Recommended Minimal CSS elements
/* prevents overlong text without spaces
from poking out the side of div.post-content */
div.post-content {
overflow:hidden;
}
/* prevents floated blocks from poking
out the bottom of the post-content div */
div.post-content-footer {
clear:both;
}
As much as web developers complain about the lack of standards support in Internet Explorer (when they’re developing on Firefox), it’s really quite another ballgame confronting the variety of syndication standards and newsreaders out there. I was recently responsible for developing and implementing a new feed generation mechanism for the O’Reilly Network family of sites (oreillynet.com, windowsdevcenter.com, macdevcenter.com, linuxdevcenter.com, onjava.com, ondotnet.com, onlamp.com, perl.com, xml.com, among others) that would bring up our standards support and allow us to include some additional content in our feeds like graphics and enclosures.
When the Atom 1.0 standard was released, I was able to have our new feeds compliant that afternoon. The problem of course is that there’s been a lag in the Atom 1.0 support in the newsreaders out there. Case in point. The other day I removed the rel="alternate" attribute from the atom:link element–I was informed it was actually optional. So I was not surprised this morning to get two bug reports from Safari RSS users that post titles were no longer linking to the actual post entry.
I put the rel="alternate" back in and Safari RSS again links to our posts. Yey. rel="alternate" is mandatory for Safari RSS. We’ve gotten reports that Akregator (a KDE newsreader) is complaining about our Atom feeds. NetNewsWire 2.0.1 which supposedly supports Atom 1.0 does not find any items in our feeds. Bloglines performs admirably, but removes whitespace around links in atom:summary elements. The good news is that if you plug our feeds into the Feed Validator, we get a thumbs up.
Hopefully these issues will be hashed out as the standard is more widely adopted. In the meantime, any of our Atom 1.0 feeds are also available in either the RSS 1.0 or the RSS 2.0 format. So if the Atom Mac DevCenter feed (http://www.oreillynet.com/pub/feed/3) is not working for you, you can request the RSS 2.0 version by adding ?format=rss2 to the URL: http://www.oreillynet.com/pub/feed/3?format=rss2. Cool huh?
This post first appeared on From the Belly of the Beasts, a weblog from some of the people who build O’Reilly websites.
One of my biggest pet peeves is the misuse of the word “blog” when referring to a single post on a weblog. I was just reading A Rendezvous With Microsoft’s Deep Throat (how could you not with a title like that?) and noticed at the end of the article a header that read “For some of Mini’s most popular blogs, check out:” followed by a list of popular posts.
Unfortunately this misuse exists here at O’Reilly, as we have bloggers who submit their posts into one big system (weblogs.oreilly.com) without any sort of individual blog identity or blog name. Since the traditional notion of a blog (definition: a collection of posts composed by a single person [or cabal], ordered in reverse chronological order) doesn’t really exist, people’s posts are referred to as “weblogs” (e.g. Todd Ogasawara’s author page) which can be filtered by author or topic.
As we continue to develop and improve the O’Reilly Network, my hope is that we can organize our bloggers around subject oriented group blogs—and start referring to posts as posts.
This post first appeared on From the Belly of the Beasts, a weblog from some of the people who build O’Reilly websites.